The Political Economy of Cognition: stitching the threads, drawing the path (Part 5 of 5)
I arrive at the last text of this series with a sense (rare, and useful) of having found a problem whose conceptual architecture is not yet consolidated in the literature, and to which my training allows a singular entry. I want, in this closing, to do three things: make explicit the synthesis that connects the four layers I developed; articulate the relationship between this program of reflection and my doctoral thesis, which has a different object but compatible toolkit; and map four research questions that this synthesis suggests for the medium-term horizon.
The unifying thesis
I will state the thesis as synthetically as possible, and then unpack it.
Vitrinization, the burnout society, the degraded equilibrium of platforms, the transformation of public deliberation by generative AI – all these phenomena are contemporary instances of a single object: the political economy of cognition under personalized choice architectures at scale. The transversal operator that connects all layers is framing.
The intuition is the following. Framing, as Tversky and Kahneman demonstrated in 1981, is the elementary cognitive gesture by which the presentation of a problem produces the preference about the problem. That gesture can operate:
- At an individual scale – a human interlocutor, a therapist, a laboratory experiment.
- At an algorithmic scale – the TikTok feed, the Google ranking, the order of search results.
- At a strategic scale – behavioral advertising that orbits political conflict, electoral microtargeting.
- At an epistemic scale – the LLM response that summarizes a complex debate, the AI that assists the decision-maker.
At each scale, framing operates with the same formal structure but at radically different magnitudes. A Tversky-Kahneman experiment affects dozens of subjects. A recommendation algorithm operates on billions. An LLM response cuts across millions of queries per day. The magnitude is new; the mechanism, not.
The consequence is that problems that previously seemed to belong to separate domains – individual cognitive biases, institutional design, platform regulation, AI governance – are, in fact, instances of the same problem. And they should be analyzable with a common vocabulary.
How the four layers stitch together
To briefly recapitulate:
The cognitive layer (click to see) establishes the microfoundation. Framing acts on the individual, producing preferences contingent on the mode of presentation. Tversky-Kahneman, and the work I did in my master’s thesis on framing in GMCR applied to the Cocó viaducts conflict, provide the starting point – with the important methodological caveat that elicitation of these preferences is itself subject to framing, configuring a recursion that is part of the method and cannot be eliminated from it.
The strategic layer (click to see) shows how individuals whose preferences depend on presentation produce, in aggregate, collective equilibria. Le Bon, Freud, and Türcke supply the historical lineage of the problem of crowds; Schelling, Festinger, and Akerlof-Kranton supply the modern game-theoretic vocabulary. The result, under the current architecture of platforms, is a Nash equilibrium of mutual exhaustion – vitrinization as the dilemma of the attention commons.
The institutional layer (click to see) shows that the architecture under which these equilibria form is not given by natural law. Castells provides the broad sociological frame, with the network society as a historical construction in dispute; Acemoglu and Johnson, in Power and Progress, show the generic thesis of technological underdetermination; Sunstein, with the notion of sludge, provides the operational instrument. The European DSA, the Australian law of 2024, and the Brazilian Bill 2630/2020 are institutional experiments in progress, whose empirical effects are beginning to be measured.
The algorithmic layer (click to see) shows that the entry of generative AIs adds a new layer of cognitive mediation that acts recursively on the three earlier ones. It amplifies or substitutes for human System 2 (Stiegler as pharmakon); it redistributes productivity unequally (Brynjolfsson, Li, and Raymond); it closes the reflexive training-production-training circuit (Rahwan and team; emerging literature on model collapse); and it calls into question Lévy’s bet on collective intelligence – when the collective comes to include non-human agents, the concept needs to be rediscussed.
The stitching: the four layers form a stack. Each layer constrains the layer above and modifies the layer below. Layer 4 produces content that affects the framing of Layer 1; Layer 1 produces preferences that aggregate into the equilibrium of Layer 2; Layer 2 produces phenomena that motivate interventions in Layer 3; Layer 3 designs the environment in which Layer 4 is trained. The system is closed, and therefore requires systemic analysis.
Why this synthesis is a contribution
There is a piece of literature for each layer. There is little literature – almost none in the lusophone space – that integrates the four. There are books in the philosophy of technique (Stiegler, Han, Türcke, Sibilia), in the political economy of technology (Acemoglu-Johnson, Zuboff), in the sociology of the network society (Castells), in behavioral economics (Thaler-Sunstein, Kahneman, Sunstein-Sibony-Kahneman in Noise), and in applied game theory (Schelling, and more recently the work of Acemoglu-Ozdaglar-Siderius). There is also the technical literature on LLMs and machine behavior (Rahwan and team, Brynjolfsson, the alignment community).
Little of this material talks to itself. Philosophers do not model; modelers do not philosophize. Behavioral economists usually stop at Layer 1; game theorists usually stop at Layer 2; political scientists go to Layer 3 but rarely connect it to the quantitative toolkit of the previous ones. The AI community has its own journals, conferences, and vocabulary, with little interface with the political economy of information.
My position combines a toolkit from game theory (GMCR), behavioral economics (framing effects), agent-based modeling (current focus of the doctorate), concrete institutional experience (Government of Ceará, Mayor’s Office of Fortaleza, UNICEF projects), and active interest in generative AI. It is a rare combination (I think), and I have discovered, writing this series, to be an operative combination. It allows formulating questions that no discipline, in isolation, formulates.
Articulation with the doctoral thesis
I want to be clear about how this series relates to the work I have been developing in the doctorate, because clarity matters.
My thesis, at the School of Economics of the University of Porto, investigates the conditions under which cooperation emerges among cognitively heterogeneous agents in agent-based models. It is a theoretical-methodological problem, not a substantive problem about social networks. It has a defined scope, supervision, schedule, and does not overlap with the object of this series.
But the relationship between the two is precise and fertile. ABM with cognitively heterogeneous agents is exactly the natural toolkit to quantitatively investigate the substantive phenomena this series maps. Schelling, who sustains much of the argument of Layer 2, is the grandfather of the methodology. Vitrinization, seen through the lens of Layer 2, is a problem of emergent cooperation (or its failure) among cognitively heterogeneous agents under a specific incentive architecture – exactly the kind of problem ABM is built to investigate.
The best formulation of the relationship is therefore: the thesis develops the toolkit; this program of reflection maps the substantive domain in which that toolkit can be, in parallel and future research, applied. The two works feed each other – the conceptual clarity gained here orients the methodological choices of the thesis; the technical rigor of the thesis provides the instrument to return to these questions with greater robustness in parallel papers and on the post-doctoral horizon.
Four research questions for the horizon
The four questions I list below are, in my assessment, the most promising for a medium-term research program – not for the current thesis, which has its own scope, but for what comes after and for parallel papers that naturally connect to the toolkit I am consolidating.
Question 1: ABM modeling of the dilemma of the attention commons with cognitively heterogeneous agents.
How does one model, in ABM, the emergence (or non-emergence) of cooperation in environments where agents have different susceptibilities to framing, different weights for social comparison, different bounded-rationality frontiers? Applied to the problem of vitrinization: under what parametric conditions (cognitive heterogeneity, intensity of algorithmic framing, exit cost) does an equilibrium of mutual exhaustion emerge? Which perturbations in the architecture displace the system into other basins of attraction? It is a question that naturally connects the thesis toolkit to the substantive domain of this series, and that could generate a sequence of articles on the post-thesis horizon.
Question 2: Preference elicitation under framing recursion – honest protocols.
Recognizing that the instrument of preference measurement is subject to the same bias it studies, is it possible to design elicitation protocols that internalize this recursion as part of the method? A convincing answer would involve triangulation among direct elicitation, revealed preferences, and experiments with varied framings – and, ideally, formal models of the distortion that the protocol itself introduces. It would be a methodological contribution of interest to all applied work in GMCR and in modeled conflict in general. It has direct affinity with what I learned in the master’s thesis.
Question 3: Algorithmic framing as treatment variable in electoral behavior.
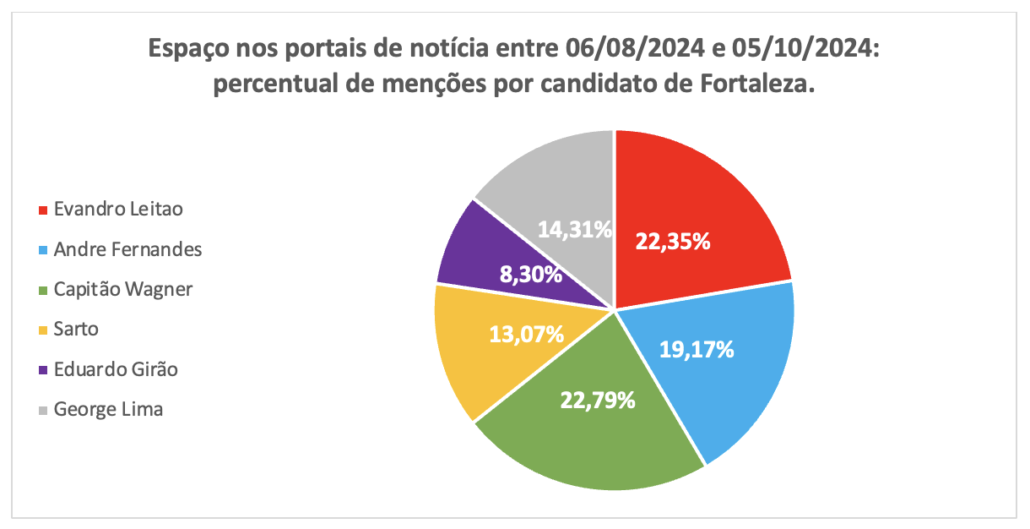
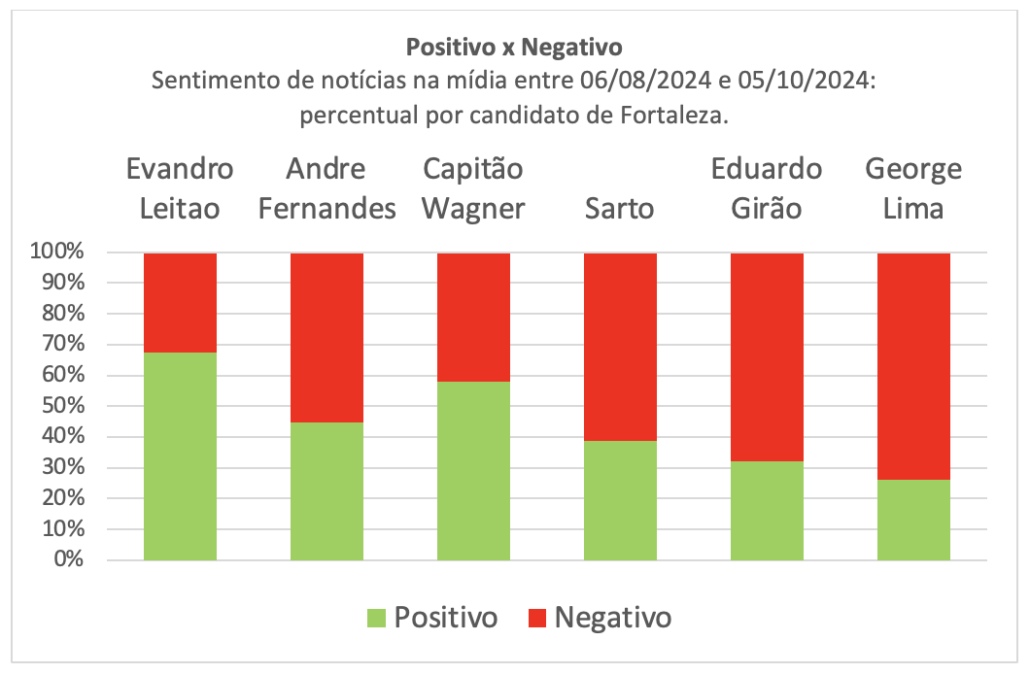
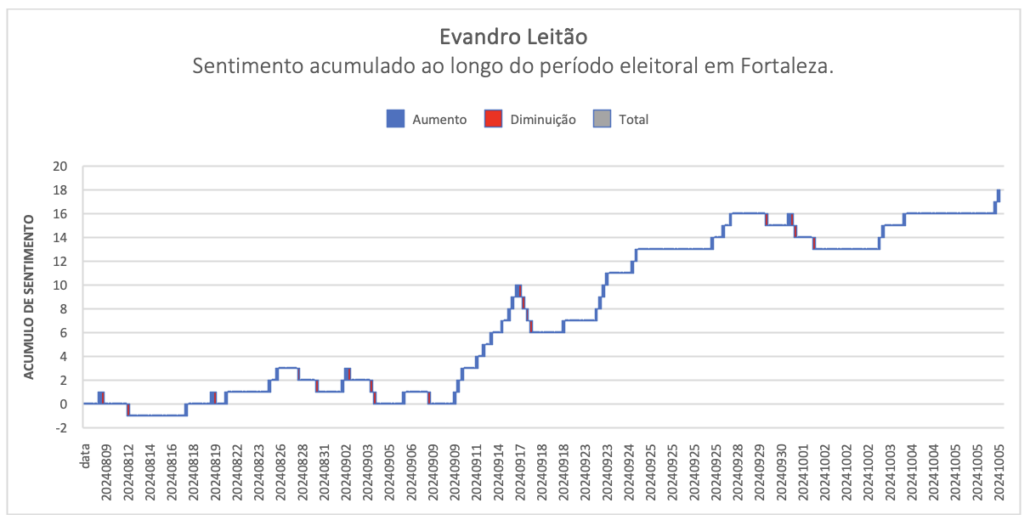
Is it possible to design quasi-experimental studies that isolate the effect of algorithmic framing on electoral behavior? I have a descriptive pilot on the blog itself – the analysis of media sentiment in the 2024 Fortaleza municipal elections. What is missing is moving from description to causal identification. There is starting literature, dominated by studies with privileged access to platform data; the interesting question is what can be done with public Brazilian and Portuguese data, mobilizing observational causal inference (synthetic control, discontinuity in algorithmic changes, instruments through exogenous exposure shocks).
Question 4: Human-AI coupling in political decision-making – experiment.
How does human-AI coupling change the quality of collective decision in conflict problems? More specifically: when a decision-maker consults an LLM to analyze a conflict, does the framing the model produces in its response alter the equilibrium of the conflict? And in which direction – convergence or divergence? Increase or reduction of epistemic diversity?
It is, in my reading, the most original and potentially impactful question. Possible design: an experiment in which real decision-makers solve conflicts modeled in GMCR – or in ABM with humans and AI agents interacting in the same environment – half with LLM assistance and half without, measuring the stability of the equilibrium reached, the quality of deliberation, and the polarization of preferences before and after. It connects Layers 1, 2, and 4 directly, and opens exactly the technical space my thesis is consolidating: ABM with cognitively heterogeneous agents, now extended to include machine agents alongside human agents.
Closing
I began this series trying to name a diffuse unease – a structural fatigue, a vitrinization that seems to define the present. I end it with a conceptual architecture and a parallel research program.
What happened in the middle was the realization, which I consider useful, that we are not facing separate problems – privacy, polarization, digital mental health, automation, AI governance. We are facing manifestations of a unified problem: how societies organize, govern, distribute, and dispute the collective cognitive resource, given the mediation technologies currently available.
This problem is old at heart. It is in Plato on writing, in Le Bon on crowds, in Marx on alienation, in Adorno on the culture industry. But it takes a specific form in this decade, with specific instruments and at a specific scale. To think it well requires a vocabulary still being built, and quantitative tools still being developed – including the toolkit I am consolidating, in another front, in my thesis.
I hope this series has been a small contribution to that construction. And that it orients, in the coming years, both the doctoral work in progress and the parallel and subsequent agenda this reflection has made visible to me. I found the axis. Now it is work.
Deoclécio Paiva de Castro
Ph.D. Candidate in Economics, Faculty of Economics, University of Porto
M.Sc. in Mathematical Modeling and Quantitative Methods, UFC
B.Sc. in Industrial / Production Engineering
References
ACEMOGLU, D.; JOHNSON, S. Power and Progress: Our Thousand-Year Struggle Over Technology and Prosperity. New York: Public Affairs, 2023.
ACEMOGLU, D.; OZDAGLAR, A.; SIDERIUS, J. “A Model of Online Misinformation”. Review of Economic Studies, 2024.
AKERLOF, G. A.; KRANTON, R. E. Identity Economics: How Our Identities Shape Our Work, Wages, and Well-Being. Princeton: Princeton University Press, 2010.
BRYNJOLFSSON, E.; LI, D.; RAYMOND, L. R. “Generative AI at Work”. Quarterly Journal of Economics, vol. 140, no. 2, 2025.
CASTELLS, M. The Rise of the Network Society. Oxford: Wiley-Blackwell, 2010. [First edition: 1996.]
CASTRO, D. P. Efeito de Enquadramento no Modelo de Grafos para Resolução de Conflitos com uma Aplicação ao Conflito das Obras de Construção dos Viadutos do Cocó [Framing Effect in the Graph Model for Conflict Resolution with an Application to the Cocó Viaducts Construction Works]. Master’s thesis – Federal University of Ceará, Fortaleza, 2022.
CASTRO, D. P. “Cinturão Digital do Ceará e as mídias digitais” [The Ceará Digital Belt and Digital Media]. Proceedings of Social Media Brasil 2011, Fecomercio, São Paulo, 2011.
CASTRO, D. P. Posts on ChatGPT o1, AI, and electoral analysis. deocleciocastro.com, 2024.
FREUD, S. Civilization and Its Discontents. New York: W. W. Norton, 2010. [Original German: 1930.]
HAN, B.-C. The Burnout Society. Stanford: Stanford University Press, 2015.
HIPEL, K. W.; KILGOUR, D. M.; FANG, L. Conflict Resolution Using the Graph Model: Strategic Interactions in Competition and Cooperation. Cham: Springer, 2018.
KAHNEMAN, D. Thinking, Fast and Slow. New York: Farrar, Straus and Giroux, 2011.
LE BON, G. The Crowd: A Study of the Popular Mind. Mineola: Dover, 2002. [Original French: 1895.]
LÉVY, P. Collective Intelligence: Mankind’s Emerging World in Cyberspace. New York: Plenum, 1997. [Original French: 1994.]
RAHWAN, I. et al. “Machine Behaviour”. Nature, vol. 568, pp. 477-486, 2019.
SCHELLING, T. C. Micromotives and Macrobehavior. New York: W. W. Norton, 1978.
SHUMAILOV, I. et al. “AI Models Collapse When Trained on Recursively Generated Data”. Nature, vol. 631, pp. 755-759, 2024.
SIBILIA, P. O Show do Eu: a intimidade como espetáculo [The Spectacle of the Self: intimacy as spectacle]. Rio de Janeiro: Nova Fronteira, 2008.
STIEGLER, B. Symbolic Misery, Volume 1: The Hyperindustrial Epoch. Cambridge: Polity Press, 2014.
SUNSTEIN, C. R.; SIBONY, O.; KAHNEMAN, D. Noise: A Flaw in Human Judgment. New York: Little, Brown, 2021.
TÜRCKE, C. Erregte Gesellschaft: Philosophie der Sensation. Munich: C. H. Beck, 2002.
TVERSKY, A.; KAHNEMAN, D. “The Framing of Decisions and the Psychology of Choice”. Science, vol. 211, no. 4481, pp. 453-458, 1981.
ZUBOFF, S. The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power. New York: Public Affairs, 2019.